GPU Programming¶
CPU parallelization and operator fusion is important, but when you really need efficiency and scale, specialized hardware is critical. It is really hard to exaggerate how important GPU computation is to deep learning: it makes it possible to run many models that would have been intractable even just several years ago.
Writing code of GPUs requires a bit more work than the CPU parallelization examples. GPUs have a slightly different programming model than CPUs, which can take some time to fully understand. Luckily though, there is a nice Numba library extension that allows us to code for GPUs directly in Python.
Getting Started¶
For Module 3, you will need to either work in an environment with a GPU available or utilize Google Colab. Google Colab provides free GPUs in a Python notebook setting. You can change the environment in the menu to request a GPU server.
We recommend working in your local setup and then cloning your environment on to a notebook:
>>> !git clone {GITHUB_PATH}
>>> !pip install -r requirements.txt
>>> !pip install -e .
You can run your tests with the following command:
>>> python -m pytest -m test3_3
CUDA¶
The most commonly used programming model for GPUs in deep learning is known as CUDA. CUDA is a proprietary extension to C++ for Nvidia devices. Once you fully understand the terminology, CUDA is a relatively straightforward extension to the mathematical code that we have been writing.
The main mechanism is thread. A thread can run code and store a small amount of states. We represent a thread as a little robot:

Each thread has a tiny amount of fixed local memory it can manipulate, which has to be constant size:

Threads hang out together in blocks. Think of these like a little neighborhood. You can determine the size of the blocks, but there are a lot of restrictions. We assume there are less than 32 threads in a block:

You can also have square or even cubic blocks. Here is a square block where the length and width of the neighborhood are the block size:
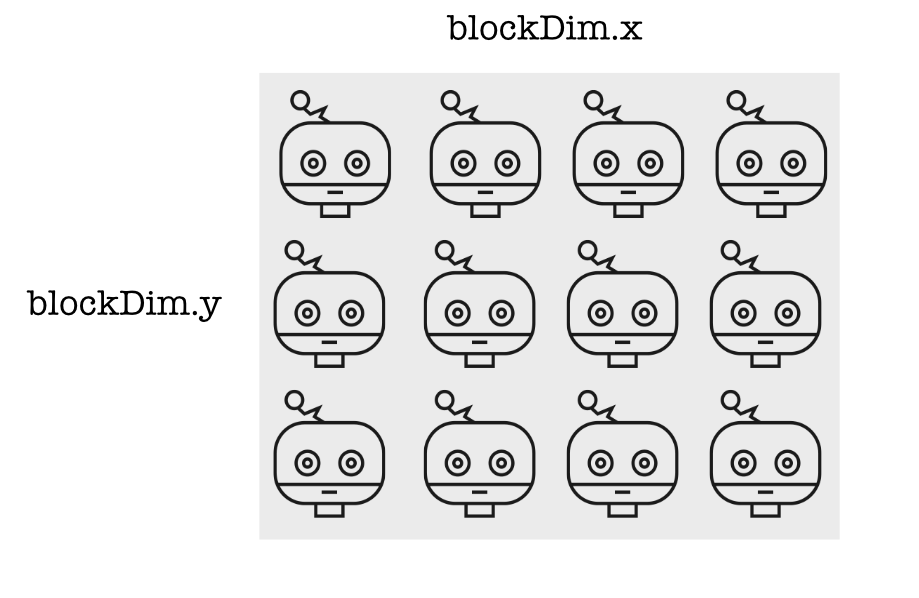
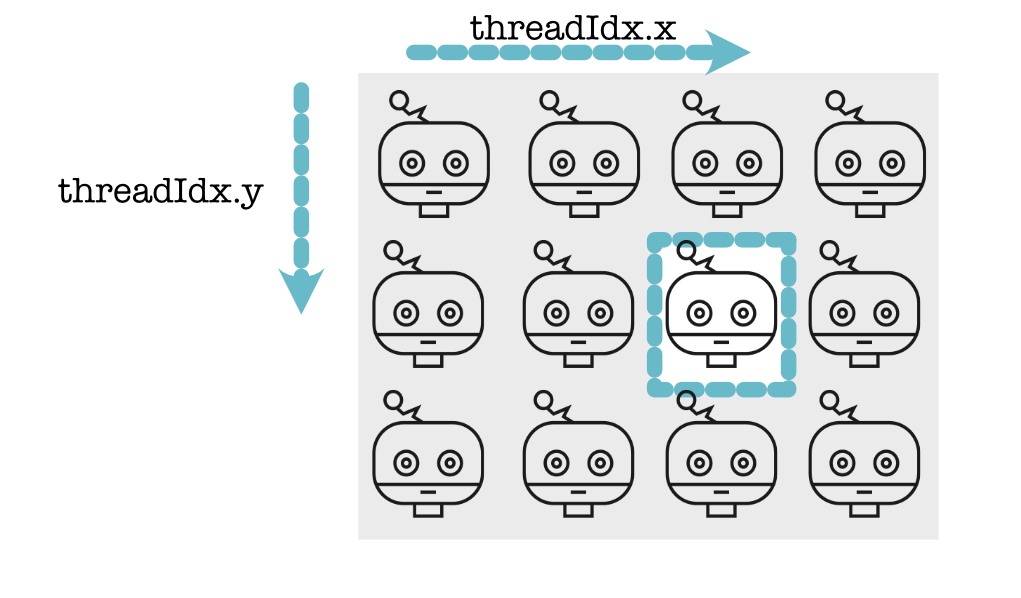
Each thread knows exactly where it is in the block. It gets this information in local variables telling it the thread index.
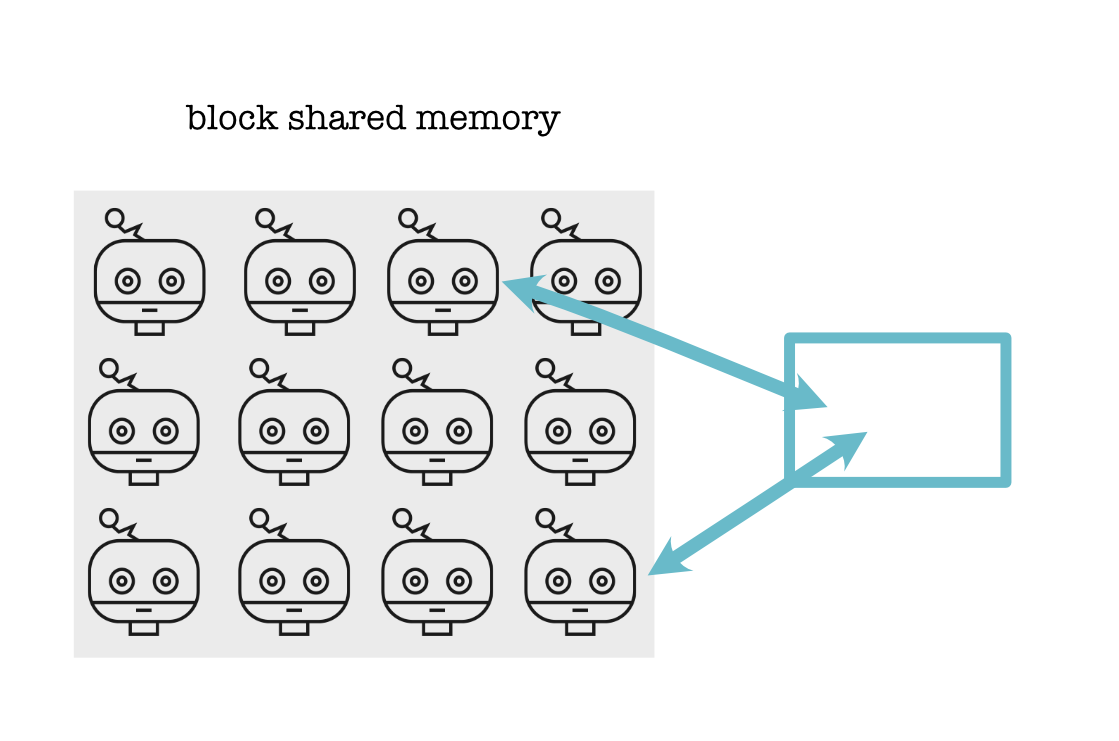
Threads in the same block can also talk to each other through shared memory. This is another constant chunk of memory that is associated with the block and can be accessed and written to by all of these threads:
Blocks come together to form a grid. Each of the blocks has exactly the same size and shape, and all have their own shared memory. Each thread also knows its position in the global grid:
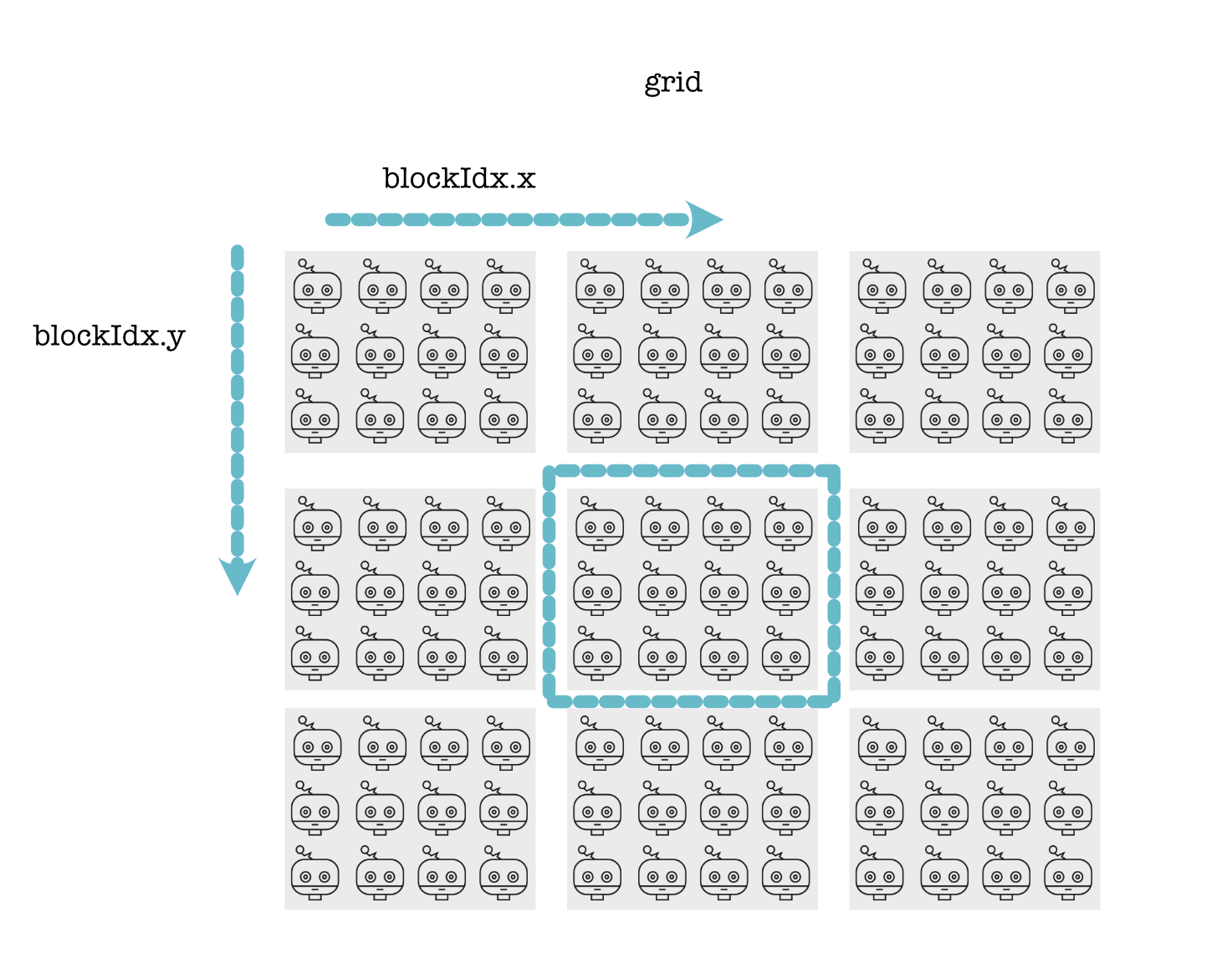
For instance, we can compute the global position x, y for a thread as:
x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
Now here comes the interesting part. When you write code for CUDA, you have to code all of the threads with the same code at the same time. Each thread behaves in lockstep running the same function:
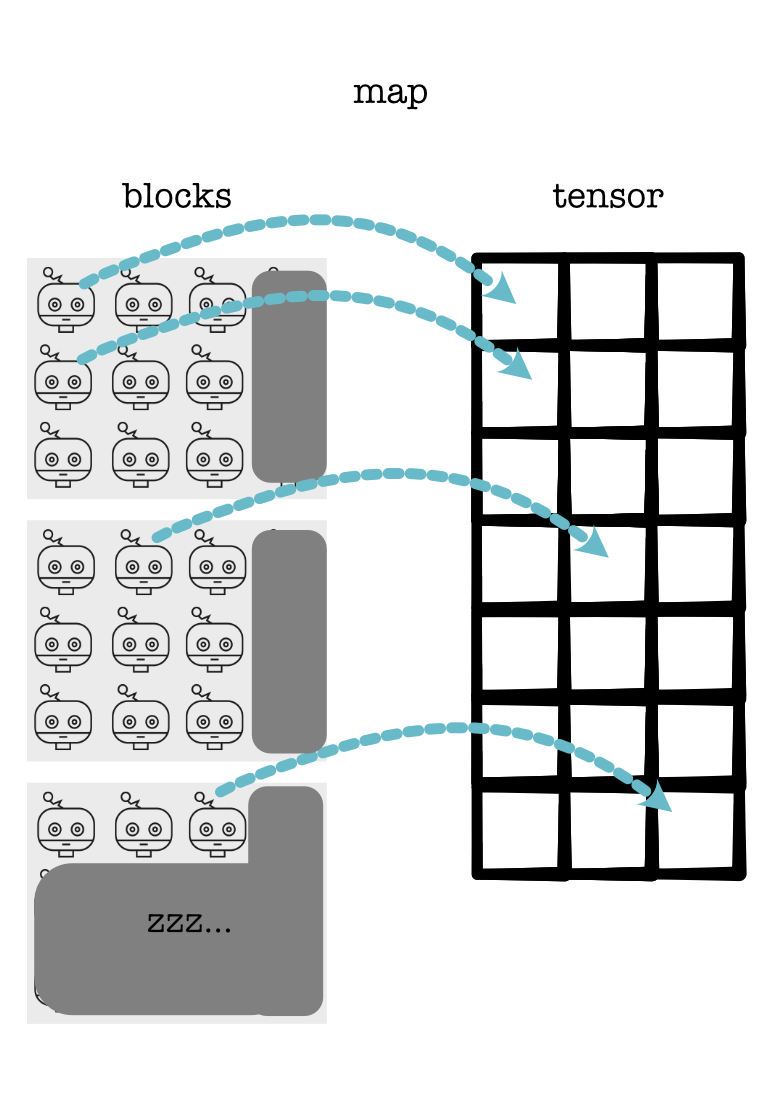
In Numba, you can write the thread instructions as a single function:
# Helper function to call in CUDA
@cuda.jit(device=True)
def times(a, b):
return a * b
# Main cuda launcher
@cuda.jit()
def my_func(in, out):
# Create some local memory
local = cuda.local.array(5)
# Find my position.
x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
# Compute some information
local[1] = 10
# Compute some global value
out[x, y] = times(in[x, y], local[1])
Note that we cannot call the above function directly: we need to launch it with instructions for how to set up the blocks and grid. Here is how you do this with Numba:
threadsperblock = (4, 3)
blockspergrid = (1, 3)
my_func[blockspergrid, threadsperblock](in, out)
This sets up a block and grid structure similar to the map function mentioned earlier. The code in my_func is run simultaneously for all the threads in the structure. However, you have to be a bit careful as some threads might compute values that are outside the memory of your structure:
# Main cuda launcher
@cuda.jit()
def my_func(in, out):
# Create some local memory
local = cuda.local.array(5)
# Find my position.
x = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
y = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
# Compute some information
local[1] = 10
# Guard some of the threads.
if x < out.shape[0] and y < out.shape[1]:
# Compute some global value
out[x, y] = times(in[x, y], local[1])